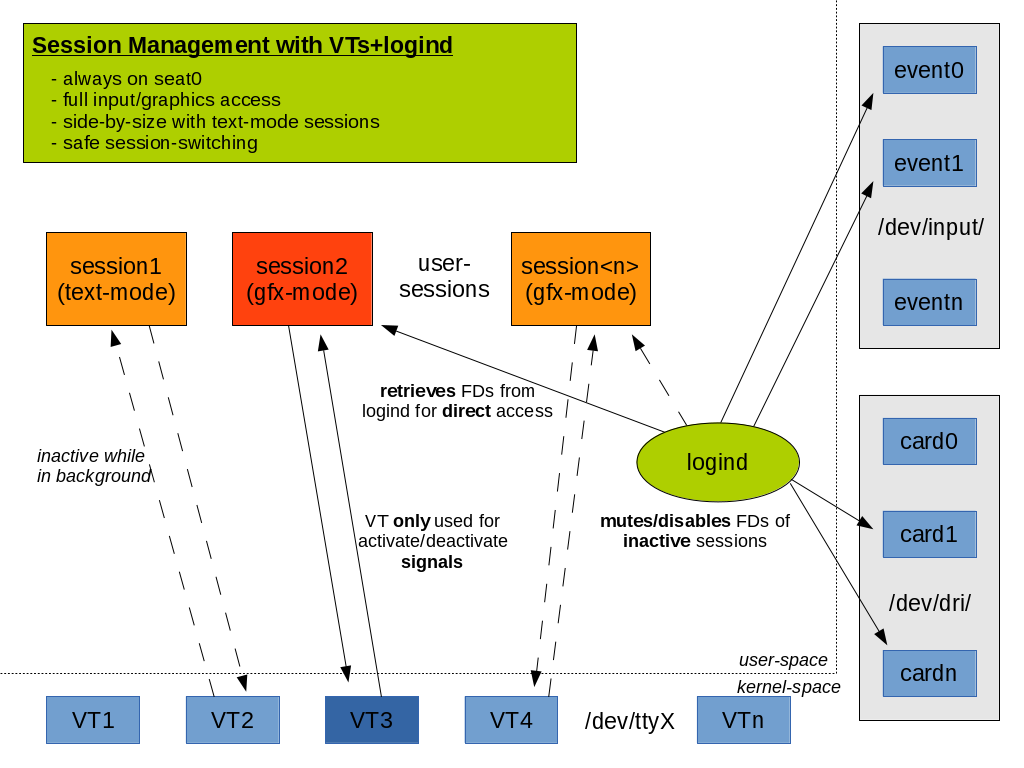
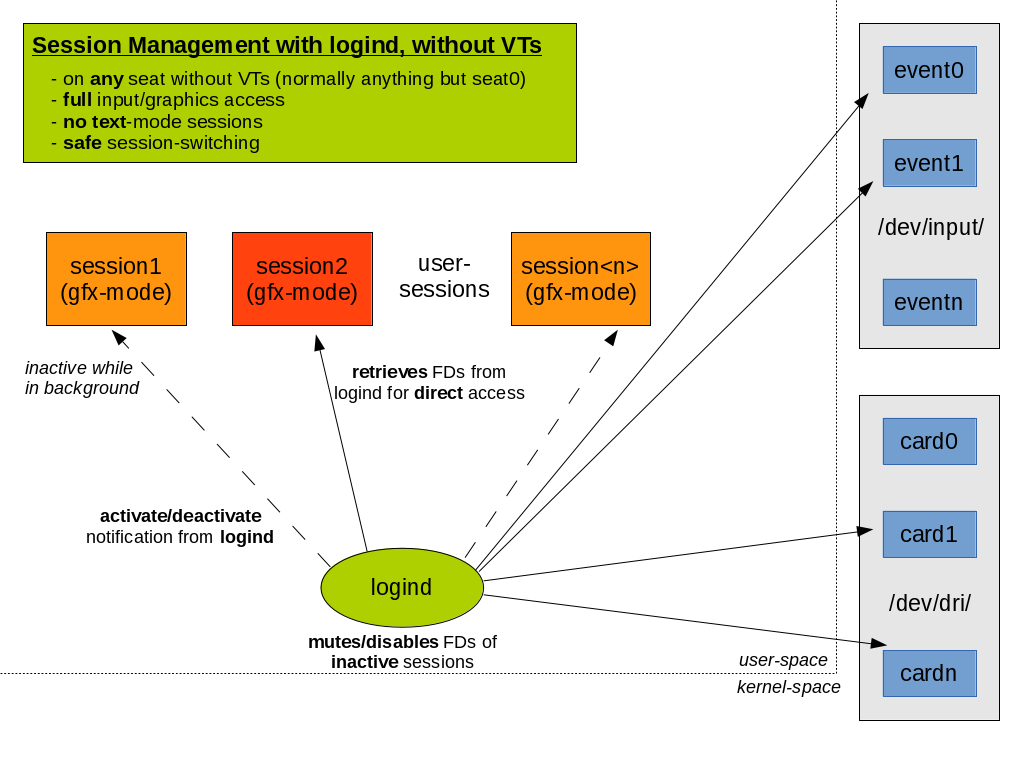
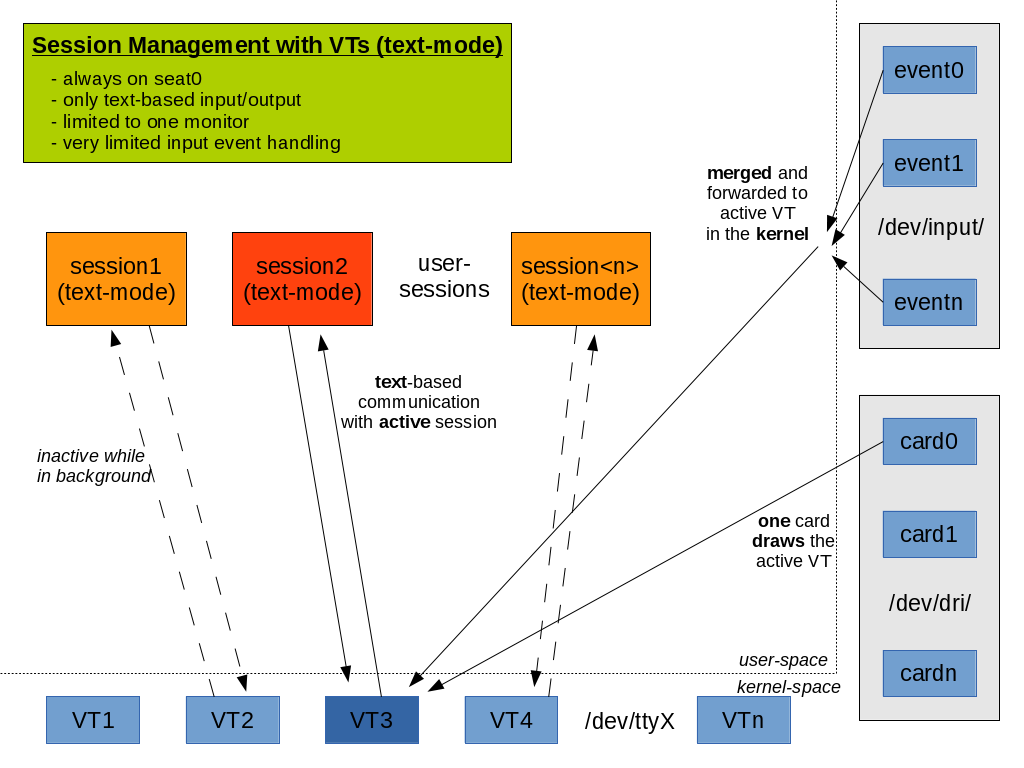
You’re a developer and you know AF_UNIX? You used it occasionally in your code, you know how high-level IPC puts marshaling on top and generally have a confident feeling when talking about it? But you actually have no clue what this fancy new kdbus is really about? During discussions you just nod along and hope nobody notices?
Good.
This is how it should be! As long as you don’t work on IPC libraries, there’s absolutely no requirement for you to have any idea what kdbus is. But as you’re reading this, I assume you’re curious and want to know more. So lets pick you up at AF_UNIX and look at a simple example.
AF_UNIX
Imagine a handful of processes that need to talk to each other. You have two options: Either you create a separate socket-pair between each two processes, or you create just one socket per process and make sure you can address all others via this socket. The first option will cause a quadratic growth of sockets and blows up if you raise the number of processes. Hence, we choose the latter, so our socket allocation looks like this:
int fd = socket(AF_UNIX, SOCK_DGRAM | SOCK_CLOEXEC | SOCK_NONBLOCK, 0);
Simple. Now we have to make sure the socket has a name and others can find it. We choose to not pollute the file-system but rather use the managed abstract namespace. As we don’t care for the exact names right now, we just let the kernel choose one. Furthermore, we enable credential-transmission so we can recognize peers that we get messages from:
struct sockaddr_un address = { .sun_family = AF_UNIX };
int enable = 1;
setsockopt(fd, SOL_SOCKET, SO_PASSCRED, &enable, sizeof(enable));
bind(fd, (struct sockaddr*)&address, sizeof(address.sun_family));
By omitting the sun_path part of the address, we tell the kernel to pick one itself. This was easy. Now we’re ready to go so lets see how we can send a message to a peer. For simplicity, we assume we know the address of the peer and it’s stored in destination.
struct sockaddr_un destination = { .sun_family = AF_UNIX, .sun_path = "..." };
sendto(fd, "foobar", 7, MSG_NOSIGNAL, (struct sockaddr*)&destination, sizeof(destination));
…and that’s all that is needed to send our message to the selected destination. On the receiver’s side, we call into recvmsg to receive the first message from our queue. We cannot use recvfrom as we want to fetch the credentials, too. Furthermore, we also cannot know how big the message is, so we query the kernel first and allocate a suitable buffer. This could be avoided, if we knew the maximum package size. But lets be thorough and support unlimited package sizes. Also note that recvmsg will return any next queued message. We cannot know the sender beforehand, so we also pass a buffer to store the address of the sender of this message:
char control[CMSG_SPACE(sizeof(struct ucred))];
struct sockaddr_un sender = {};
struct ucred creds = {};
struct msghdr msg = {};
struct iovec iov = {};
struct cmsghdr *cmsg;
char *message;
ssize_t l;
int size;
ioctl(fd, SIOCINQ, &size);
message = malloc(size + 1);
iov.iov_base = message;
iov.iov_len = size;
msg.msg_name = (struct sockaddr*)&sender;
msg.msg_namelen = sizeof(sender);
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = control;
msg.msg_controllen = sizeof(control);
l = recvmsg(fd, msg, MSG_CMSG_CLOEXEC);
for (cmsg = CMSG_FIRSTHDR(&msg); cmsg; cmsg = CMSG_NXTHDR(&msg, cmsg)) {
if (cmsg->cmsg_level == SOL_SOCKET && cmsg->cmsg_type == SCM_CREDENTIALS)
memcpy(&creds, CMSG_DATA(cmsg), sizeof(creds));
}
printf("Message: %s (length: %zd uid: %u sender: %s)\n",
message, l, creds.uid, sender.sun_path + 1);
free(message);
That’s it. With this in place, we can easily send arbitrary messages between our peers. We have no length restriction, we can identify the peers reliably and we’re not limited by any marshaling. Sure, we now dropped error-handling, event-loop integration and ignored some nasty corner cases, but that can all be solved. The code stays mostly the same.
Congratulations! You now understand kdbus. In kdbus:
- socket(AF_UNIX, SOCK_DGRAM, 0) becomes open(“/sys/fs/kdbus/….”, …)
- bind(fd, …, …) becomes ioctl(fd, KDBUS_CMD_HELLO, …)
- sendto(fd, …) becomes ioctl(fd, KDBUS_CMD_SEND, …)
- recvmsg(fd, …) becomes ioctl(fd, KDBUS_CMD_RECV, …)
Granted, the code will look slightly different. However, the concept stays the same. You still transmit raw messages, no marshaling is mandated. You can transmit credentials and file-descriptors, you can specify the peer to send messages to and you got to do that all through a single file descriptor. Doesn’t sound complex, does it?
So if kdbus is actually just like AF_UNIX+SOCK_DGRAM, why use it?
kdbus
The AF_UNIX setup described above has some significant flaws:
- Messages are buffered in the receive-queue, which is relatively small. If you send a message to a peer with a full receive-queue, you will get EAGAIN. However, since your socket is not connected, you cannot wait for POLLOUT as it does not exist for unconnected sockets (which peer would you wait for?). Hence, you’re basically screwed if remote peers do not clear their queues. This is a really severe restriction which makes this model useless for such setups.
- There is no policy regarding who can talk to whom. In the abstract namespace, everyone can talk to anyone in the same network namespace. This can be avoided by placing sockets in the file system. However, then you lose the auto-cleanup feature of the abstract namespace. Furthermore, you’re limited to file-system policies, which might not be suitable.
- You can only have a single name per socket. If you implement multiple services that should be reached via different names, then you need multiple sockets (and thus you lose global message ordering).
- You cannot send broadcasts. You cannot even easily enumerate peers.
- You cannot get notifications if peers die. However, this is crucial if you provide services to them and need to clean them up after they disconnected.
kdbus solves all these issues. Some of these issues could be solved with AF_UNIX (which, btw., would look a lot like AF_NETLINK), some cannot. But more importantly, AF_UNIX was never designed as a shared bus and hence should not be used as such. kdbus, on the other hand, was designed with a shared bus model in mind and as such avoids most of these issues.
With that basic understanding of kdbus, next time a news source reports about the “crazy idea to shove DBus into the kernel”, I hope you’ll be able to judge for yourself. And if you want to know more, I recommend building the kernel documentation, or diving into the code.